引言:
了解视频中的身体个人行为在视频监管、无人驾驶及其安全防范措施等方面拥有普遍的应用前景。现阶段视频中的身体个人行为分类科学研究是对切分好的视频精彩片段开展1人的个人行为分类。对视频中的身体个人行为分类科学研究早已从起初的几类简易人体动作到几乎包括全部日常日常生活的好几百类个人行为。近几年来根据RGB视频数据信息的优秀深层个人行为分类模型可以分成三类:根据双流构架的、根据循坏神经元网络RNN的和根据3D卷积神经网络的。文中将详解前二种深层个人行为分类模型。
一、视频行为分类
现阶段身体行为识别的分析关键分成两个子每日任务:个人行为分类和时钟频率个人行为检验。个人行为分类一般是对切分好的视频精彩片段开展个人行为分类,每一个视频精彩片段仅包括一个个人行为案例。殊不知,现实生活中绝大多数视频全是未切分的长视频,因而时钟频率个人行为检验每日任务从没切分的长视频中检验出个人行为的逐渐、完毕時间及其个人行为类别,一段长视频中一般含有一个或好几个个人行为案例。个人行为分类是时钟频率个人行为检验的基本,时钟频率个人行为检验是比个人行为分类更繁杂的科学研究每日任务,个人行为分类的經典实体模型(如TSN,C3D,I3D等)也被普遍用以时钟频率个人行为检验每日任务之中。如今视频中身体行为识别的探讨工作中大多数都专注于提升个人行为分类模型的特性,而且科学研究最普遍的是对1人个人行为的鉴别。
二、评定数据
针对数据驱动的机器学习方式而言,巨大的视频信息量显而易见可以提高实体模型的特性。文中采用了全新且经营规模更高视频数据kinetics,来各自较为全新的根据RGB视频键入信息的个人行为分类模型的特性,与此同时也应用典型性的视频数据UCF101, 协助剖析和较为經典的深层个人行为分类模型。UCF 101和Kinetics数据的评定衡量规范全是是均值精度平均值(mAP)。在对视频中的个人行为开展分类时,每一个视频精彩片段都是会预测分析一个个人行为标识。假定有C个个人行为类别,每一个视频精彩片段都相匹配一个有C个因素的目录,每一个原素意味着着该视频归属于个人行为c的几率,并将C个类别标识依照几率值从高究竟排列。假定一共有n个视频精彩片段,并取一个视频片段的预测分析优秀率目录中的前k个值,P(k)分别是类别标识排名在前k的预测分析几率值,rel(k)是指示函数,说明第k个标识是不是真呈阳性(true positive),如果是则为1,不然为0。因而,某一个人行为类别的均值精度(AP)的计算方式是
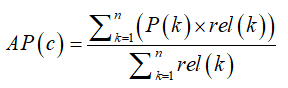
平均精度平均值(mAP)是全部类别的均值精度求合后再取平均值。

UCF 101数据一般只留预测分析几率最大的标识做为预测分析标识(k=1,top-1)。而Kinetics数据信息集中化,粗粒度的个人行为类别区划造成一个视频精彩片段很有可能含有多种多样姿势。例如,驾车”时“发信息”,“演奏尤克里里”时“跳草裙舞”,“舞蹈”时“刷牙漱口”这些。因此在Kinetics数据上开展分析时,通常挑选优秀率最多的前5个标识做为预测分析的个人行为类别标识(k=5,top-5)。文中在较为实体模型的逻辑推理速率时,采用了2个评价指标体系。一个是每秒钟帧数(FPS) ,即每秒钟实体模型可以解决的视频帧的总数。另一个是每秒钟浮点运算频次(GFLOPS)。文中中表明的GFLOPs指标值均选用32帧的视频精彩片段做为模式的键入数据信息。
三、深层个人行为分类模型
在视频身体个人行为分类的探讨中,重要且具备挑战的一个问题是怎样从视频的时钟频率层面上得到身体的健身运动信息内容。根据RGB视频的机器学习方式依据时钟频率模型方法的差异可以分成根据双流构架的,根据循坏神经元网络(RNN)的和根据3D卷积神经网络的。初期将深度神经网络方式拓展运用于RGB视频中的一个經典试着是,拓展2D卷积神经网络产生双流构架,各自来得到视频帧的空间特征及其帧间的健身运动特点。接着有科学研究将循环系统神经元网络(RNN)与卷积神经网络(CNN)融合,尝试学习培训更全局性的视频时钟频率信息内容。充分考虑视频自身是多了时间维度的3D体,3D互联网则形象化地应用3D卷积核来得到视频的空时特点。这种根据RGB视频的个人行为分类方式关键关心二点:(1)怎样在视频中获取出更具备辨别力的外型特点;(2)如何获得时钟频率上视频帧外型的更改。在详细介绍这类深层学习方法以前,迫不得已最先提一下經典的手工制作获取特点的方式iDT(improved Dense Trajectories)[1],是深度神经网络运用到视频行业以前特性最佳的方式,它根据光流跟踪图象像素数在时间段上的轨迹。该方式有一个挺大的不足之处是得到的特点层面乃至比原视频还需要高,处理速度十分慢。初期的深层学习方法在和iDT融合以后都能得到一定的作用提高。发展趋势到现在,深度神经网络方式在视频个人行为分类上的特性已较iDT有大幅提高。1、双流构架2014年Karpathy [2]等人选用2个单独流各自获得画面质量帧和高清晰度的特点,在时间段上选用慢结合的方法拓展了全部卷积层在时间段上的连通性,这也是将CNN拓展到视频个人行为分类的应用,但其特性与传统的方式iDT也有一定的差别。Simonyan初次提到根据光流的双流(two-stream)构架,各自应用视频帧和帧间的光流图象做为CNN的键入。该方式 可以说成CNN拓展到视频个人行为分类的初次十分顺利的试着,在UCF101上的精度做到了88%,好于手工制作svm算法的方式iDT。融合光流键入的双流构架的优良主要表现激起了后面对很多根据双流构架的改善。双流结合法(Two-stream Fusion) [3]在双流构架的基本上,应用VGG-net深层实体模型做为主干网,并指出在最后一个卷积层后结合特点比在全连接层以后结合特点的作用好些。充分考虑这二种双流方式没法对长期性时钟频率构造模型,时钟频率上一次仅能解决持续10帧的层叠光势流,航线则仅解决单帧图象。时钟频率切分互联网(TSN) [4]则立即对整篇视频模型,在时钟频率上把全部视频按段(segment),最终结合不一样精彩片段的类别优秀率,来得到长久的时钟频率特点,结合后的预估結果是视频级的预测分析,在UCF 101数据上的精度做到了94.2%。TSN的实体模型如下图1所显示。

图 1 时钟频率切分互联网(TSN)实体模型构架
TSN在UCF 101数据上的特性主要表现早已十分优异。Lan等人[5]明确提出深层部分特点(DVOF),在TSN实体模型的基本上运用深层互联网获取部分特点,将汇聚部分特点产生的全局性特点导入到浅表层互联网开展分类,来改正部分特点学习培训到的错误的行为标识信息内容。时钟频率关联逻辑推理(TRN)[6]是2017年MIT周博磊高手根据TSN改善的一个很具备创造性的探讨工作中。TRN在时间维度上可以获取不一样尺寸的视频特点,随后应用多层感知机(MLP)结合不一样时域和频域的帧间关联,用以学习培训和逻辑推理视频帧中间的時间相互依赖。该办法在UCF101上的特性提升并不显著,这是由于UCF101中的视频数指的姿势在区域上的前后文关系更强,可是毕业论文在时钟频率前后文关联性更强的Something-Something[]视频数据上认证了TRN发觉视频中时钟频率关联的工作能力。根据光流的双流构架呈现了优异的特性,殊不知光流的测算必须耗费非常大的存储资源。也是有方式试着可以替代光流表明健身运动信息内容的方式,Zhang等人[7]明确提出测算健身运动矢量素材(motion vector)来替代光流做为CNN的键入,逻辑推理速率能实现每秒钟390.7帧,创作者将光流CNN中学习培训的特性和专业知识转移到健身运动矢量素材CNN中希望能填补健身运动矢量素材在粗粒度和噪音上的不够,可是最后实体模型在精度上也有非常大的放弃。以上双流方式在UCF101数据上的功能如表1。
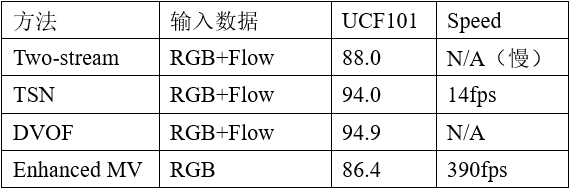
表 1 双流构架在UCF101数据上的特性比照
2、RNN互联网CNN是非常典型的前馈控制神经元网络,以上根据CNN互联网的实体模型一次仅能解决比较有限的视频帧,如典型性的TSN解决一次处理10个视频帧并根据时钟频率汇聚方法得到更长久的视频级的预测分析,C3D则一次解决16帧,I3D则是一次处理64帧照片。殊不知在现实生活中,许多普遍的人们个人行为例如握手,喝酒,通电话,或徒步、游水等反复姿势的个人行为通常不断数十秒超越数千视频帧。循环系统神经元网络(RNN)的循环结构,可以将此前的信息内容联接到当前任务,容许信息内容长时间存在,因而可以有效地对编码序列构造模型。殊不知初期的 RNN互联网不可以对长期性的相互依赖开展模型,也不可在相当长一段时间内储存有关以往键入的信息内容。理论上讲一个充分大的RNN应当可以模型随意复杂性的编码序列,殊不知在练习RNN的时候会发生梯度消失和梯度爆炸问题。RNN互联网的组合,长短期记忆互联网(LSTM)则解决了这个问题。LRCN[8]将LSTM用以在时间序列分析上对2D卷积网络获取的帧特点模型,发觉如此的网络架构明显增强了这些姿势延迟时间长度姿势的静态数据外型易搞混的个人行为分类精度。Ng[9]等人较为了特点池化和LSTM二种时钟频率汇聚方法,将CNN輸出的帧级特点汇聚成视频级,表明在融合视频编码序列中远期的数据可以完成更佳的视频分类,毕业论文中也根据双流构架各自应用RGB和光流图象做为键入。Sharma 等人[10]开拓性地在根据LSTM的互联网中导入了注意力机制,明确提出了soft-attention LSTM,该实体模型让互联网可以关心视频帧中与个人行为类别有关的地区。VideoLSTM[11]则是在soft-attention LSTM的基本上层叠了一个RNN用以健身运动模型而且安装了增强版的专注力实体模型,殊不知繁杂的模式构造并没显著地提升特性。以上实体模型全是运用了CNN LSTM的方式,应用CNN获取视频帧特点,并且用LSTM立即汇聚好几个视频帧来得到视频时钟频率上的相互依赖。殊不知,根据那样的形式学习培训到的健身运动隐含地假定了视频中的健身运动在不一样的区域地方上是静止不动的。Sun[12]等人明确提出了Lattice LSTM(L2STM),通过学习记忆力模块在差异的空间地方的单独掩藏情况变换来拓展LSTM,合理地提高了時间上动态性模型工作能力。以上根据RNN互联网的视频中身体个人行为分类方式在UCF 101数据上的精度如表2所显示。
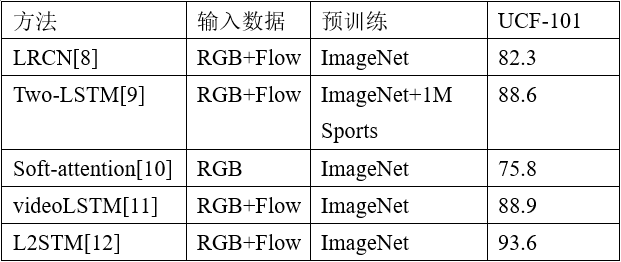
表 2 在UCF101数据上较为RNN个人行为分类模型